A strange thing about my job is that, although we’re all about supporting K-12
education data interoperability, we don’t actually work with any K-12 data. We
build software, and others use it to collect data from disparate data sources
into a single, unified, and standardized data set. But that does’t stop me from
thinking about how data should be used.
On a flight out to the #STATSDC2023 conference hosted by the National Center for
Educational Statistics (my first time at this event), I finally wrote down my
personal principles for ethical / responsible use of data and AI. Many have
written about responsible use of data; there is nothing ground breaking here.
Yet it feels meaningful, even if only for myself, to acknowledge “out loud” the
values and principles that I wish to hold myself accountable for whenever I do
use data, encourage others to make use of data, allow my own data to be used,
etc.
☝Note First draft, 2023-08-10
Virtues and Values
As a person of faith, I tend to think of virtues before I think of values.
Virtues are the spiritual foundations, and values are culturally-relevant
extensions of those virtues. While there are countless variations on virtues and
values, those below can serve as guiding lights for the principles that follow.
“Truthfulness is the foundation of all human virtues.” `Abdu’l-Bahá
| Virtue |
Value Correlate(s) |
| truthfulness |
transparency, honesty, truth-seeking |
| justice |
equity, independence, consensus |
| nobility |
human dignity, recognition of aspirations, privacy |
Guiding Principles
Admittedly this is a hodge-podge list of principles, with no attempt to be
systematic at this time.
Data Source Transparency: Retain as much information about data sources as
possible. Vet them for integrity, completeness, appropriateness, and manner of
collection. Only use ethically sourced information. Insure personal data usage
corresponds to subject’s intent. Give credit where credit is due.
Example: avoid (shady) data aggregator / brokers.
Algorithmic Transparency: Prefer open algorithms. Look for, or conduct,
audits to assess accuracy, applicability to the desired use case(s), and
potential for biases. Look for explainability and ensure there is a reasonable
human appeals process. Does a great deep learning model really outweigh having
a good and explainable decision tree or a regression model?
Example: Do AI and cheat detection systems have low false positives? Are there
clear appeals mechanisms? Have they been cross-validated against different
subgroups to ensure they do not introduce biases? Can you explain why a person’s
application is rejected or a promotion has been offered to one and not another
when AI is involved in the process?
Side note: Does use of generative AI really matter in the given context?
Equity: Do not be content with doing no harm, rather seek to uplift
marginalized perspectives and peoples. Consider institutional biases that may
influence raw data (over and under representation). Consider environmental
factors that may impact some populations, independent of or in concert with
other demographic factors. Be mindful of accidental proxies.
Examples: Account for ethnic / racial disparities in policing, gender disparities in
surveying, and geographic impacts such as longer bus rides to schools (“all the
XYZ kids have poor attendance” might be due to late buses, or working parents,
nothing to do with ethnicity).
Don’t feel virtuous by avoiding use of race while at the same time analyzing
based on income, if income and race are highly correlated in a particular area.
Statistical Honesty: Use appropriate sample sizes and/or statistical tests
to confirm assumptions. Cross validate results. Use large iterations when
bootstrapping and repeat to insure stability of results.
Privacy: Practice appropriate anonymization and apply “need to know” (least
privilege) restrictions. Watch out for small sample sizes that can
unintentionally reveal identity. Use the least personal data available and
relevant for the analysis.
Examples: Imagine an analysis that predicts a certain outcome for a target
demographic, and the dataset only contains a few people from that demographic.
Apply a filter by zip code. How hard is it to guess the person / household?
Can you use census block instead of street address? Zip code instead of census
block? Age range instead of birth year?
Consensus and Review: Seek review of data, algorithms, and outcomes from
other experts and/or affected parties. Work to achieve consensus on techniques
and communication. Start early to avoid the trap of stubbornly clinging to a
misdirected idea.
Destiny: as a matter of justice, of nobility, and of truthfulness: be on
guard for predictions becoming destiny.
Example: Whether policing on the street or teachers disciplining students, a
prediction that one group will have more criminal / behavioral incidents easily
leads to paying more attention to that group, ignoring other groups, and thus
detecting (or “inventing”) more ill behavior in that group - thus reinforcing
the original prediction.
Sources of Inspiration
Speaking of giving credit where credit is due, here are some sources that have
helped shape my thinking on this topic:
And articles, asides, and conversations that are too numerous to remember or
cite.
Also see references in:



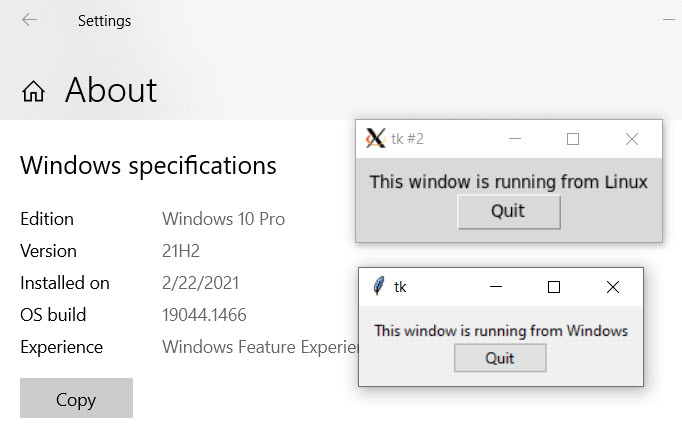 Screenshot shows that I’m running Windows 10, and shows a small GUI window opened
from both Powershell and from Bash using the same Python script.
Screenshot shows that I’m running Windows 10, and shows a small GUI window opened
from both Powershell and from Bash using the same Python script.